Yamu
この記事は
pandasのgroupbyメソッドを
利用して層別散布図を作ることを
目的としています
[PR]※本サイトには、プロモーションが含まれています
| 合わせて読みたい | 記事の内容 |
| 散布図,相関関係,相関係数について簡単に説明する | 3つの内容を簡単に説明しています |
| 【Python】散布図を用いたアヤメの特徴分析方法 | アヤメの種類ごとの特徴量をデータで示しています |
| Pandasのデータ構造: SeriesとDataFrameを理解する | seriesとdataFrameについて簡単に解説します |
groupbyメソッドとは ?
groupbyメソッドは
読み込んだデータを特定のキーに基づいて
グループ化するための方法です
例えばこんなデータセットがあります
| カテゴリー | 値 |
| A | 10 |
| B | 20 |
| C | 30 |
| A | 40 |
| B | 10 |
カテゴリーごとの合計値を求めたいです
groupbyを使えば簡単に値を求めることができます
import pandas as pd
# サンプルデータフレームの作成
data = {
'カテゴリ': ['A', 'B','C','A', 'B'],
'値': [10, 20, 30, 40, 10]
}
df = pd.DataFrame(data)
grouped = df.groupby("カテゴリ")["値"].sum()
print(grouped)実行結果
カテゴリ
A 50
B 30
C 30
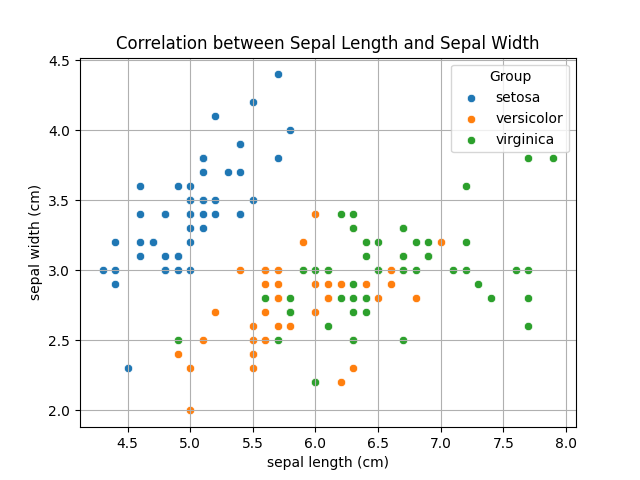
Name: 値, dtype: int64層別散布図とは ?
層別散布図とは、散布図の一種
データポイントを特定のカテゴリや層を選択して
異なるグループ間の関係や
パターンを視覚的に示す図です
今回はdfメソッドのgroupbyを利用して
アヤメの種類ごとに
散布図のプロットの色を変えることを
したいと思います
フィッシャーのアヤメのデータセット
統計学者又、生物学者であるロナルド・フィッシャー
によって収集された有名なデータです
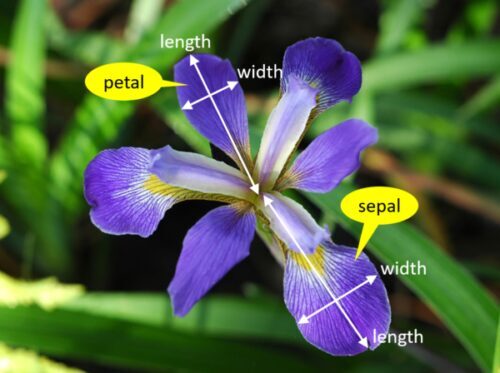
各花の種類について、以下のように構成されています
| 列名 | 列名の意味 |
| sepal length(cm) | がく片の長さ |
| sepal width(cm) | がく片の幅 |
| petal length(cm) | 花弁の長さ |
| petal width(cm) | 花弁の幅 |
| Species | 花の種類(setosa, versicolor, virginica) |
3種類のアヤメ

データセットの項目の測定箇所
Yamu
このデータは
3種のアヤメの特徴を
示しているんですね!
下記コードで
irisのデータセットを取得
してください
import pandas as pd
from sklearn.datasets import load_iris
# Irisデータセットをロード
iris = load_iris()
# データをpandasのDataFrameに変換
iris_df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
# target列を数値から種の名前に変換
species = [iris.target_names[i] for i in iris.target]
iris_df['Species'] = species
# CSVファイルに保存
csv_file_path = 'iris_dataset_with_species.csv'
iris_df.to_csv(csv_file_path, index=False)
print(f"Irisデータセットを {csv_file_path} に保存しました。")groupbyメソッドを利用して層別散布図を作る
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# データの読み込み、Speciesをインデックスにする
df = pd.read_csv("iris_dataset_with_species.csv", index_col='Species')
print(df.head(2))
# Speciesごとにデータをグループ分けして散布図をプロットする関数
def plot_grouped_scatter(dataframe):
grouped = dataframe.groupby(dataframe.index)
for name, group in grouped:
sns.scatterplot(data=group, x='sepal length (cm)', y='sepal width (cm)', label=name)
plt.xlabel('sepal length (cm)')
plt.ylabel('sepal width (cm)')
plt.title("Correlation between Sepal Length and Sepal Width")
plt.legend(title='Group', loc='upper right')
plt.grid(True)
# プロットを保存
plt.savefig('scatter_plot.png')
# プロットを表示
plt.show()
# 関数を呼び出してプロット
plot_grouped_scatter(df)
実行結果
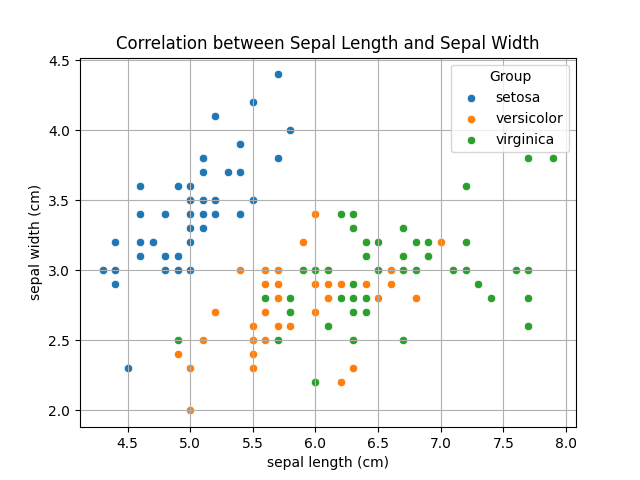
下記の部分でデータをアヤメの種類ごとに
分けグラフ化しています
# インデックス(花の種類毎)にデータを分ける
grouped = dataframe.groupby(dataframe.index)
# 層別散布図を作るコード
for name, group in grouped:
sns.scatterplot(data=group, x='sepal length (cm)', y='sepal width (cm)', label=name)
