Yamu
今回は2つのデータを
データフレームから
結合する
方法を説明します
[PR]※本サイトには、プロモーションが含まれています
目次
今回紹介する結合
| コード | 意味 |
| pd.merge(df1,df2, on =’キー’) | 2つのデータの共通キーを利用してデータを結合する関数 |
pd.mergeでデータを結合してみる
pd.merge(df1, df2, on=’key’)
というコードでデータを結合をします
on=’Key’でキーを指定します
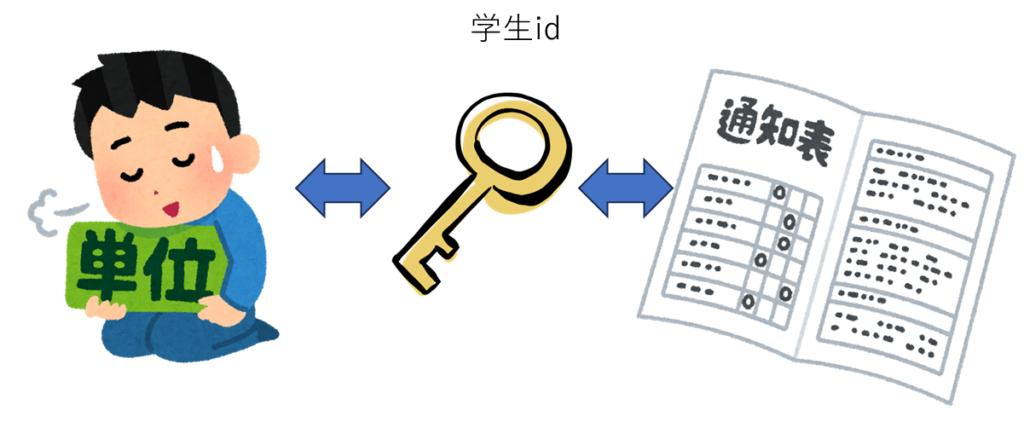
データ1に生徒idと名前が入っているデータがあります
| student_id | name |
| 1 | 田中 |
| 2 | 山田 |
| 3 | Bob |
データ2に生徒idと各生徒の成績が入っているデータがあります
| student_id | 数学 | 英語 | 国語 | 物理 |
| 1 | A | C | C | B |
| 2 | C | A | A | C |
| 3 | C | A | D | C |
二つのデータセットで共通する項目は
student_id()です
この学生idをキーにしてデータを紐づけます
import pandas as pd
# 学生情報
data1 ={
"student_id" :[1, 2, 3],
"name" : ["田中", "山田", "Bob"]
}
# 成績情報
data2 = {
"student_id": [1, 2, 3],
"数学": ["A", "C", "C"],
"英語": ["C", "C", "A"],
"国語": ["C", "A", "D"],
"物理": ["B", "C", "C"]
}
student_df = pd.DataFrame(data1)
grades_df = pd.DataFrame(data2)
print(student_df)
print(grades_df)
print(pd.merge(student_df,grades_df, on ="student_id"))実行結果
student_id name
0 1 田中
1 2 山田
2 3 Bob
student_id 数学 英語 国語 物理
0 1 A C C B
1 2 C C A C
2 3 C A D C
student_id name 数学 英語 国語 物理
0 1 田中 A C C B
1 2 山田 C C A C
2 3 Bob C A D Cmergeの結合オプション how
結合を行うmerge関数は
howオプションがあります
| how | 意味 |
| outer | 全てのキーで結合 |
| inner | 共通キーのみ結合 |
| left | 片方のキーで結合 |
| right | 片方のキーで結合 |
pd.merge(df1, df2, on =”key”, how =”outer”)
outer結合は
指定したキーに基づいて
全てのデータを結合し
対応するキーがない場合は
NaN(欠損値)を表示します
pd.merge(student_df,grades_df, on ="student_id", how = "outer")実際に確認してみます
生徒idと名前が入っているデータ1に
id 4の佐藤君を追加します
data1 ={
"student_id" :[1, 2, 3, 4],
"name" : ["田中", "山田", "Bob","佐藤"]
}生徒idと成績データに
id 6の人のデータを追加します
# 成績情報
data2 = {
"student_id": [1, 2, 3, 6],
"数学": ["A", "C", "C", "E"],
"英語": ["C", "C", "A","E"],
"国語": ["C", "A", "D","E"],
"物理": ["B", "C", "C","E"]
}下記のコードでhow =”outer”の挙動を確認します
import pandas as pd
# 学生情報
data1 ={
"student_id" :[1, 2, 3, 4],
"name" : ["田中", "山田", "Bob","佐藤"]
}
# 成績情報
data2 = {
"student_id": [1, 2, 3, 6],
"数学": ["A", "C", "C", "E"],
"英語": ["C", "C", "A","E"],
"国語": ["C", "A", "D","E"],
"物理": ["B", "C", "C","E"]
}
student_df = pd.DataFrame(data1)
grades_df = pd.DataFrame(data2)
print(student_df)
print(grades_df)
print(pd.merge(student_df,grades_df, on ="student_id", how = "outer"))実行結果
student_id name
0 1 田中
1 2 山田
2 3 Bob
3 4 山田
student_id 数学 英語 国語 物理
0 1 A C C B
1 2 C C A C
2 3 C A D C
student_id name 数学 英語 国語 物理
0 1 田中 A C C B
1 2 山田 C C A C
2 3 Bob C A D C
3 4 山田 NaN NaN NaN NaNYamu
キーの要素全てで
結合されています
対応していないものは
NaN
内部結合
inner結合は一致するキー
のみ結合されます
先のコードのouterをinnerに書き換えてください
pd.merge(student_df,grades_df, on ="student_id", how = "inner")実行結果
student_id name
0 1 田中
1 2 山田
2 3 Bob
3 4 佐藤
student_id 数学 英語 国語 物理
0 1 A C C B
1 2 C C A C
2 3 C A D C
3 6 E E E E
student_id name 数学 英語 国語 物理
0 1 田中 A C C B
1 2 山田 C C A C
2 3 Bob C A D CYamu
共通キー1,2,3のみ
結合されています
左側結合
left結合は
データ1のキーで
結合するオプションです
pd.merge(student_df,grades_df, on ="student_id", how = "left")実行結果
student_id name
0 1 田中
1 2 山田
2 3 Bob
3 4 佐藤
student_id 数学 英語 国語 物理
0 1 A C C B
1 2 C C A C
2 3 C A D C
3 6 E E E E
student_id name 数学 英語 国語 物理
0 1 田中 A C C B
1 2 山田 C C A C
2 3 Bob C A D C
3 4 佐藤 NaN NaN NaN NaNYamu
データ1のキーが
1,2,3,4なので
データ1のキーで
結合していることが
分かりますね
右側結合
right結合は
データ2のキーで
結合するオプションです
pd.merge(student_df,grades_df, on ="student_id", how = "right")実行結果
student_id name
0 1 田中
1 2 山田
2 3 Bob
3 4 佐藤
student_id 数学 英語 国語 物理
0 1 A C C B
1 2 C C A C
2 3 C A D C
3 6 E E E E
student_id name 数学 英語 国語 物理
0 1 田中 A C C B
1 2 山田 C C A C
2 3 Bob C A D C
3 6 NaN E E E EYamu
データ2のキーが
1,2,3,6なので
データ2のキーで
結合していることが
分かりますね
参考文献

東京大学のデータサイエンティスト育成講座 ~Pythonで手を動かして学ぶデ―タ分析~ | 塚本邦尊, 山田典一, 大澤文孝, 中山浩太郎, 松尾 豊[協力] |本 | 通販 | Amazon
Amazonで塚本邦尊, 山田典一, 大澤文孝, 中山浩太郎, 松尾 豊の東京大学のデータサイエンティスト育成講座 ~Pythonで手を動かして学ぶデ―タ分析~。アマゾンならポイント還元本が多数。塚本邦尊, 山田典一, 大澤文孝, 中山浩太郎, 松尾 豊作品ほか、お急ぎ便対象商品は当日お届けも可能。また東京大学のデータ...
amzn.to