
Yamu
今回はpandasの
データ構造
seriesを
紹介します
| 合わせて読みたい |
| 【pandas】DataFrameのデータ構造を理解する |
Series(シリーズ)
一次元の配列で、インデックスを持つデータ構造です
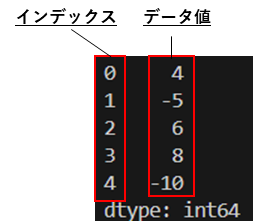
import pandas as pd
obj = pd.Series([4,-5,6,8,-10])
print(obj)実行結果を確認すると
インデックスが左側
データ値が右側になります
データとインデックスは紐づいているので
obj[i]で要素を呼び出すことができます
import pandas as pd
obj = pd.Series([4,-5,6,8,-10])
l = len(obj.index)
for i in range(l):
print(f"obj[{i}] = {obj[i]}")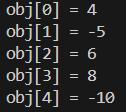
データ操作が簡単
条件指定によるフィルタリング
スカラー値の演算
ソーティングの例です
import pandas as pd
obj = pd.Series([4,-5,6,8,-10])
# フィルタリング
obj2 = obj[obj > 2]
print(obj2)
# スカラー値の掛け算
obj3 = obj *2
print(obj3)
#ソーティング
sorted_obj = obj.sort_values()
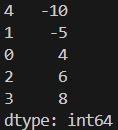
print(sorted_obj)obj2
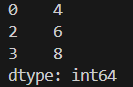
obj3
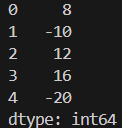
obj4
Yamu
データ操作を行っても
元のインデックスは
保持されるんですね
reset_indexメソッドでインデックスをリセットできる
reset_indexを利用して
加工したデータのインデックスを
リセットできます
import pandas as pd
obj = pd.Series([4,-5,6,8,-10])
# フィルタリング
obj2 = obj[obj > 2].reset_index(drop = True)
print(obj2)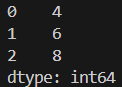
インデックスをディクショナリ形式で渡すことが出来る
インデックスを辞書型で渡すことができます
import pandas as pd
data ={"東京" : 4,"秋田" : -5,"大阪" : 6,"奈良" : 8,"北海道" : -10}
obj = pd.Series(data)
print(obj)

