
Yamu
今回は
Pythonのライブラリ
pandasのデータ構造
SeriesとDataFrameを
紹介していきます
[PR]※本サイトには、プロモーションが含まれています
Pandasとは
データの構造化や操作、分析、可視化など
さまざまなデータ処理タスクを行うための
pythonライブラリ
例えばデータの中から
ある条件だけを満たす行を抽出したり
データを結合する操作が出来ます。
Pandasのデータ構造
主に「DataFrame」と「Series」という
2つの主要なデータ構造を提供しています
DataFrameは行と列の両方を持つ2次元のデータ構造
Seriesは、1次元のデータ構造
Seriesのデータ構造
Seriesは1次元配列のようなオブジェクト
Seriesは値とインデックス(キー)
が含まれます
シリーズを作成するコードを書いて値を
確認していきます。
import pandas as pd
# Pandasライブラリを使用してPythonでシリーズ(Series)オブジェクトを作成し、それを変数objに割り当てる
obj = pd.Series([2,3,6,7,10])
print(obj)
インデックスに
0からN-1までの連続した整数が
自動で振り分けられ
各インデックスには
64ビットの整数型データが
格納されていることが確認できます。
Seriesはフィルタリングや探索数学的な演算も出来ます。
import pandas as pd
# Pandasライブラリを使用してPythonでシリーズ(Series)オブジェクトを作成し、それを変数objに割り当てる
obj = pd.Series([2,3,6,7,10])
# フィルタリングを行い2の倍数のみobj2に格納する
obj2 = obj[obj % 2 == 0]
# 結果を表示
print(obj2)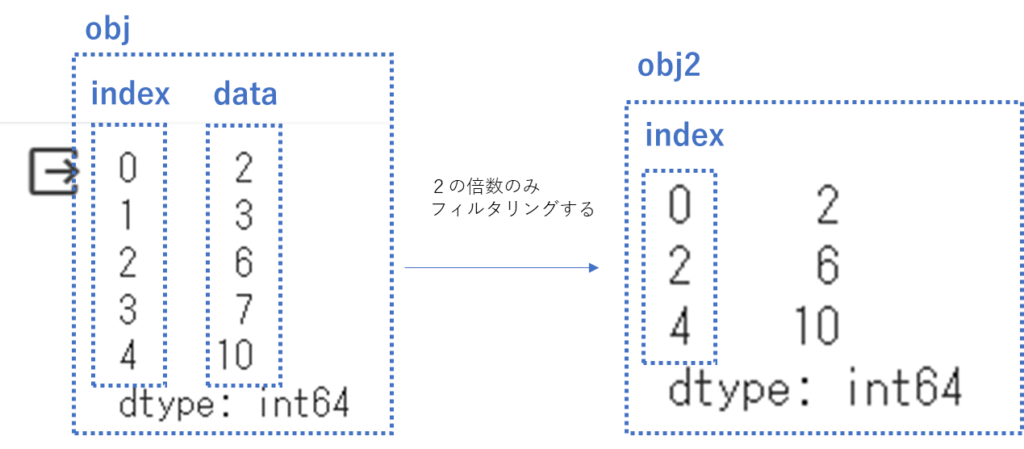
Yamu
フィルタリングした後でも
インデックスとデータの結びつきは
保持されるんですね
インデックスをリセットしたい
場合は下記のコードを利用します
# obj2のインデックスをリセット
obj2 = obj2.reset_index(drop=True)
# 結果を表示
print(obj2)
DataFrameのデータ構造
DataFrameは
インデックスカラム,データの
3要素を持つテーブル形式の
データ構造を持ちます
import pandas as pd
# DataFrameを作成するためにディクショナリ形式を修正
dic = { 'ID' : ['100' , '101' , '102','103','104'],
'City' : ['Tokyo','Osaka', 'Kyoto','Hokkaido','Tokyo'],
'Name' : ['Sato','Suzuki','Tanaka','Sasaki','Ohno'],
'Test' : ['Pass','Fail','Pass','Fail','Pass'],
}
# ディクショナリ形式をDataFrameに変換
df = pd.DataFrame(dic)
print(df)出力は

カラムとインデックスは
軸と呼ばれる
カラムとインデックスの
オブジェクトの型(クラス)を
下記のコードを先ほどのコードに
追加して確認してみる
print('カラムのオブジェクトの型は' , type(df.columns))
print('インデックスのオブジェクトの型は' , type(df.index))
インデックスカラムは両方とも
Indexオブジェクトの一種であるが
軸の方向が異なっている
インデックス→axis=0
カラム→axis=1
行インデックスと
列インデックス
と呼ばれることもある。
参考文献

Pythonによるデータ分析入門 第2版 ―NumPy、pandasを使ったデータ処理 | Wes McKinney, 瀬戸山雅人, 小林儀匡 |本 | 通販 | Amazon
AmazonでWes McKinney, 瀬戸山雅人, 小林儀匡のPythonによるデータ分析入門 第2版 ―NumPy、pandasを使ったデータ処理。アマゾンならポイント還元本が多数。Wes McKinney, 瀬戸山雅人, 小林儀匡作品ほか、お急ぎ便対象商品は当日お届けも可能。またPythonによるデータ分析入門...
amzn.to

pandasクックブック ―Pythonによるデータ処理のレシピ― | Theodore Petrou, 黒川 利明 |本 | 通販 | Amazon
AmazonでTheodore Petrou, 黒川 利明のpandasクックブック ―Pythonによるデータ処理のレシピ―。アマゾンならポイント還元本が多数。Theodore Petrou, 黒川 利明作品ほか、お急ぎ便対象商品は当日お届けも可能。またpandasクックブック ―Pythonによるデータ処理のレシピ...
amzn.to

