
Yamu
今回はpandasの
データ構造
DataFrameを
紹介します
| 合わせて読みたい |
| 【pandas】Seriesのデータ構造を理解する |
DataFrame(データフレーム)
カラムとインデックスからなる2次元のデータ構造
import pandas as pd
# データを辞書として用意
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eva'], # 文字列
'Age': [25, 30, 35, 40, 28], # 数値
'Salary': [50000, 60000, 70000, 80000, 55000] # 数値
}
# データフレームを作成
df = pd.DataFrame(data)
# データフレームを表示
print("文字列と数値を含むデータフレーム:")
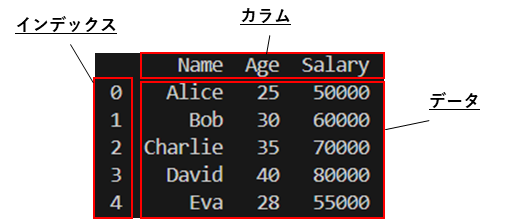
print(df)実行結果を確認すると
データフレームは
インデックス,カラム,データ
3要素から成り立っていることが確認できる
インデックス,カラム,データは
以下の方法でアクセスできる
import pandas as pd
# データを辞書として用意
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eva'], # 文字列
'Age': [25, 30, 35, 40, 28], # 数値
'Salary': [50000, 60000, 70000, 80000, 55000] # 数値
}
# データフレームを作成
df = pd.DataFrame(data)
# インデックス
index = df.index
# カラム
columns = df.columns
# データ
data = data.values
print(index.values)
print(columns.values)
print(data)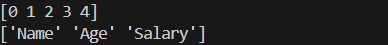
dtypesを使ってカラムのデータ型を把握する
dtypesを利用すると
カラムのデータ型を表示することができます
import pandas as pd
# データを辞書として用意
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eva'], # 文字列
'Age': [25, 30, 35, 40, 28], # 数値
'Salary': [50000, 60000, 70000, 80000, 55000] # 数値
}
# データフレームを作成
df = pd.DataFrame(data)
# データ型を表示
print(df.dtypes)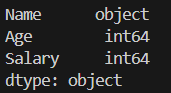
Yamu
Nameはオブジェクト型
Age, Salaryは整数型ですね
下記コードを追加すると
データフレーム内の
データ型の数を知ることができます
print(df.dtypes.value_counts())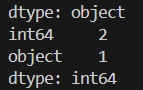
データフレームのカラム(列)はシリーズで取得できる
データフレームのカラム(列)は
1元配列series形式で取得できます
import pandas as pd
# データを辞書として用意
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eva'], # 文字列
'Age': [25, 30, 35, 40, 28], # 数値
'Salary': [50000, 60000, 70000, 80000, 55000] # 数値
}
# データフレームを作成
df = pd.DataFrame(data)
# データフレームのカラムはシリーズで取得できます
# データ型を表示
print(df["Name"])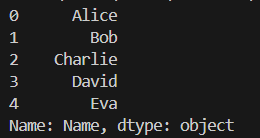
データフレームから
seriesとしてデータを
取り出すことで
様々なデータ処理を実現可能にします
参考文献

Yamu
Pandasクックブック
DataFrame解剖学より

