
pandasでデータを
読み込む際に発生する
UnicodeErrorを防ぐ方法を
紹介します
[R]※本サイトにはプロモーションが含まれています
目次
エンコーディングとは?
データの形式や表現方法を
デジタルデータに変換する技術
エンコーディングは
2つのプロセスを含んでいます
エンコード(Encode)
データをコンピュータが理解できる形式
(バイト列やビット列)に変換するプロセス
デコード(Decode)
エンコードされたデータを元の形式に戻すプロセス
文字エンコーディング
テキストの文字データを
パソコンが理解できるデータに変換するための方式
コンピュータは人間が扱う文字を
理解しているわけではありません
0と1の組み合わせである数値で意味を理解し
数値に該当する文字を表示する処理を
実行しているだけです
文字の値は文字コードとして割り当てられます
文字コードの数値の割り当て方は
様々な種類が存在しています
コンピューターは
文字の意味を理解せず
対応している数値で
どの文字が該当するか
判断しているんだね
文字コードの種類
| 文字コード種類 | 概要 | 対応文字 |
| ASCII | 米国規格協会(ANSI)によって定められたコード | アルファベット、数字、記号 |
| EBCDIC | IBM社が定めたコード | アルファベット、数字、記号 |
| S-JIS | ASCIIに対応する文字は1バイトで表現され 日本語の文字は2バイトで表現 | ASCII文字、漢字、カナ、漢字、記号 |
| EUC | UNIXといったOS上で使われる日本語文字コード | ASCII文字、漢字、カナ、漢字、記号 |
| Unicode | 各国のあらゆる文字を1つのコードで表そうとしている文字コード | 世界各国の文字 |
UnicodeDecodeError
pandasでデータを読み込む際
エンコーディングを指定しない場合
pandasはデフォルトで
UTF-8エンコーディングを仮定します
多くの場合においてうまく機能しますが
データファイルが
UTF-8以外でエンコードされている場合や
問題が発生する可能性があります。
その一つがUnicodeDecodeErrorです
UnicodeError例
下記のsample.csvからデータを読み込みたいです
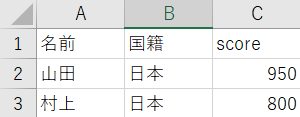
以下のようなコードを書いて読み込もうとします
# pandasでファイルを読み込む際に使用する例
import pandas as pd
file_path = "sample.csv"
df = pd.read_csv(file_path)下記のようなエラーが出ました

簡単に説明すると
pandasでデータを読み込む際
UTF-8の形式を仮定したが
上手くいかなかったということです
ファイルのエンコーディング形式を以下のコードで確認します
import chardet
def detect_encoding(file_path):
with open(file_path, 'rb') as f:
raw_data = f.read()
result = chardet.detect(raw_data)
encoding = result['encoding']
confidence = result['confidence']
return encoding, confidence
# ファイルパスを指定してエンコーディングを判定
file_path = "sample.csv"
detected_encoding, confidence = detect_encoding(file_path)
print(f"Detected encoding: {detected_encoding}, Confidence: {confidence}")実行結果
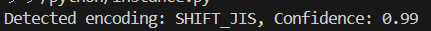
このファイルのエンコーディング形式は
shift -jisということが判明しました
なので読み込む際の形式として
shift – jisを指定してみます
import pandas as pd
file_path = "C:\\Users\\satot\\OneDrive\\デスクトップ\\python\\sample.csv"
df = pd.read_csv(file_path, encoding="Shift - jis")
print(df)実行結果

読み込めました
shift -jisでエンコーディングされている
ファイルに対してUTF – 8と仮定して
データを読み込もうとしたから
上手くいかなかったんだね

