
今回は
pd.pivot_table()
を利用して
クロス集計を行い
集計後
ヒートマップを
実装します
[PR]※本サイトにはプロモーションが含まれています
目次
クロス集計とは
異なる項目同士の関係性を
分析するための集計方法です
クロス集計の手法を具体的に説明します
顧客アンケートの集計
製品の顧客満足度調査で
年齢層と満足度をクロス集計する場合
次のような表が作成されました

集計表の数値を1つ観察をしてみます
35-44歳の年齢層の行と
アンケートで普通と
答えた人の列の重なるところを
確認してみると10と書いてあります
これは10人の35-44歳の年齢層の人が
普通と答えたことを意味しています

今回利用するデータセット
製造業の歩留まりデータセットを
利用してクロス集計表を行おうと考えています
| ロット | 投入数 | 不良数 | 材料 | 装置番号 |
| 1 | 500 | 2 | A | A1 |
| 2 | 500 | 3 | B | A2 |
| 3 | 500 | 2 | C | A3 |
| 4 | 500 | 1 | A | A4 |
| 5 | 500 | 0 | B | A2 |
| 6 | 500 | 0 | A | A3 |
| 7 | 500 | 2 | C | A1 |
| 8 | 500 | 1 | A | A2 |
| 9 | 500 | 3 | B | A4 |
| 10 | 500 | 1 | B | A2 |
このデータについて少し説明します
ロットとは ?
製品管理の最小単位
このデータを見ると500個は同じ材料、同じ装置で
作られていることがわかります
歩留まりとは ?
生産された製品の内良品の割合
例えば500個作って498個成功したら
歩留まりは
\(498/500 = 0.996\)
製品を99.6%はうまく作れることを示します
不良率とは ?
生産された製品の内不良品の割合
例えば500個作って2個不良になったら
不良率は
\(2/500 = 0.004\)
製品を0.4%はうまく作れないことを示します
装置番号と材料で投入数,不良の数を集計する
最初に材料と装置番号で投入数を
クロス集計したいと思います
下記コードでデータセットを行ってください
import pandas as pd
data_set_path = "sample_data.csv"
df =pd.read_csv(data_set_path,encoding ="UTF -8")
print(df.head(5))実行結果
ロット 投入数 不良数 材料 装置番号
0 1 500 2 A A1
1 2 500 3 B A2
2 3 500 2 C A3
3 4 500 1 A A4
4 5 500 0 B A2下記コードを加えてクロス集計を行ってください
pivot_table = pd.pivot_table(
df,
values='投入数',
index='材料',
columns='装置番号',
aggfunc='sum',
fill_value=0,
margins=True,
margins_name='total',
dropna=True
)実行結果
装置番号 A1 A2 A3 A4 total
材料
A 500 500 500 500 2000
B 0 1500 0 500 2000
C 500 0 500 0 1000
合計 1000 2000 1000 1000 5000pd.pivot_tableのオプションを説明します
| values | 集計したいデータの列名 |
| index | 行インデックス(複数指定可) |
| columns | 列ラベル(複数指定可) |
| aggfunc | 集計方法を示します/今回は合計(sum) |
| fill_value | NaN値を置き換えるための値を指定します |
| dropna | すべてNaNの列をドロップするかどうかを指定します。 デフォルトはTrue |
集計結果をヒートマップにする
集計表を視覚化します
視覚化には
ヒートマップが適しているので
ヒートマップにします
plt.figure(figsize=(10, 6))
sns.heatmap(pivot_table, annot=True, fmt="d", cmap="coolwarm", cbar=True)
plt.title('合計投入数', fontdict={'fontsize': 14, 'fontname': 'MS Gothic'})
plt.xlabel('装置番号',fontdict={'fontsize': 12, 'fontname': 'MS Gothic'})
plt.ylabel('材料', fontdict={'fontsize': 12, 'fontname': 'MS Gothic'})
plt.show()実行結果
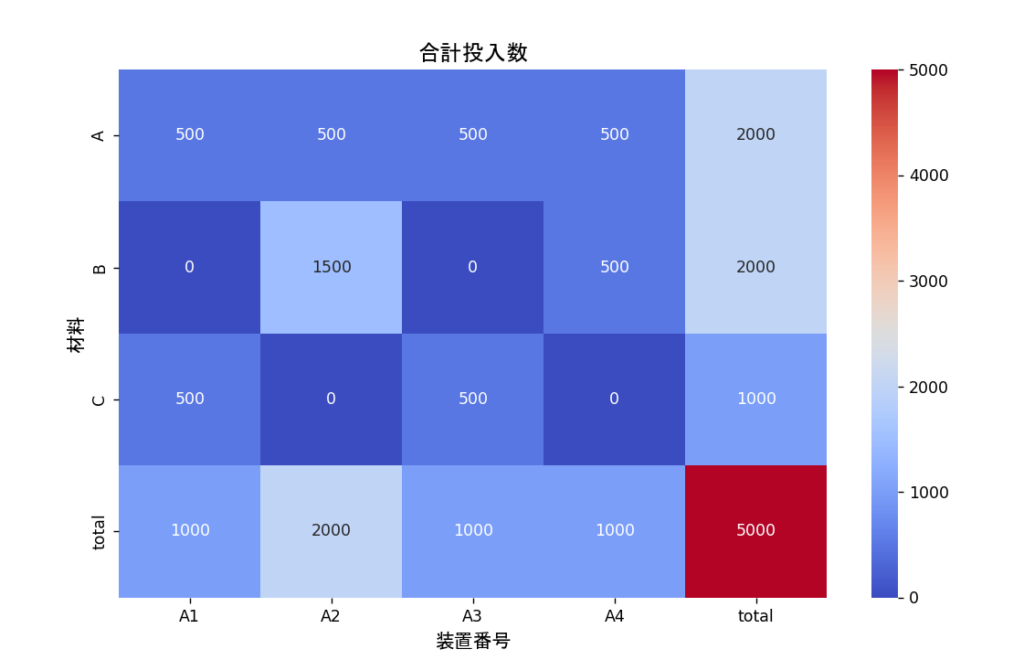
装置と材料の組み合わせで集計ができました
不良数も集計します
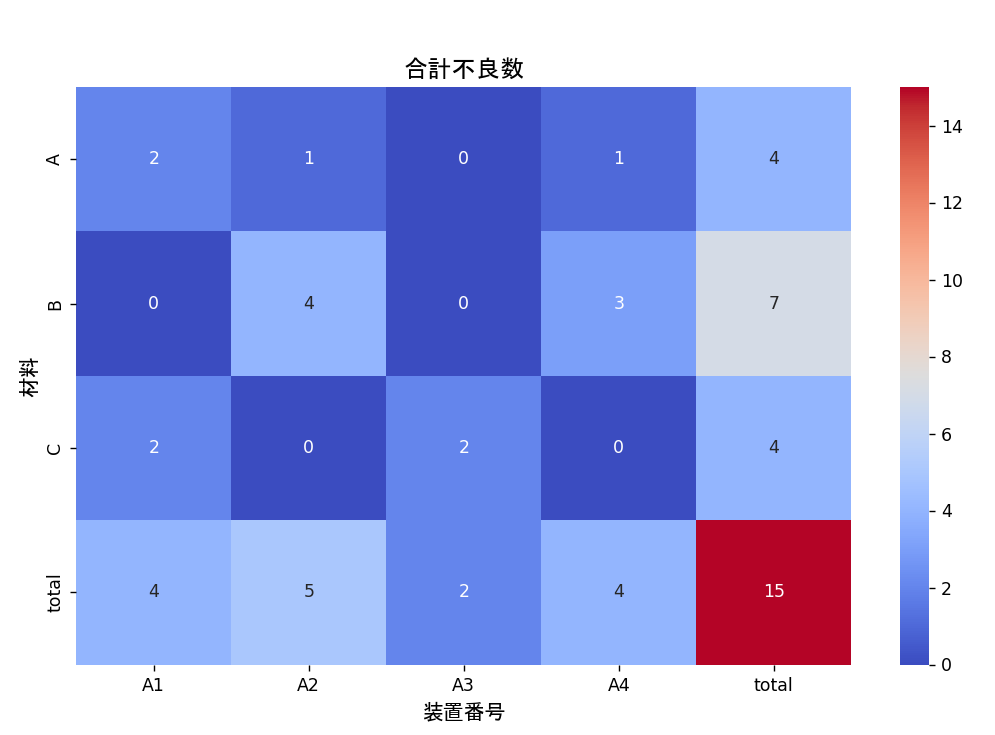
クロス集計コードを置いておきます
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
data_set_path = "sample_data.csv"
df =pd.read_csv(data_set_path,encoding ="UTF -8")
pivot_table = pd.pivot_table(
df,
values='投入数',
index='材料',
columns='装置番号',
aggfunc='sum',
fill_value=0,
margins=True,
margins_name='total',
dropna=True
)
print(pivot_table)
# ヒートマップの作成
plt.figure(figsize=(10, 6))
sns.heatmap(pivot_table, annot=True, fmt="d", cmap="coolwarm", cbar=True)
plt.title('合計投入数', fontdict={'fontsize': 14, 'fontname': 'MS Gothic'})
plt.xlabel('装置番号',fontdict={'fontsize': 12, 'fontname': 'MS Gothic'})
plt.ylabel('材料', fontdict={'fontsize': 12, 'fontname': 'MS Gothic'})
plt.show()不良率をクロス集計する
不良率の集計を行います
材料と装置番号で投入数
材料と装置番号で不良数の集計を行い
不良率の計算を行い
不良率のヒートマップを作成します
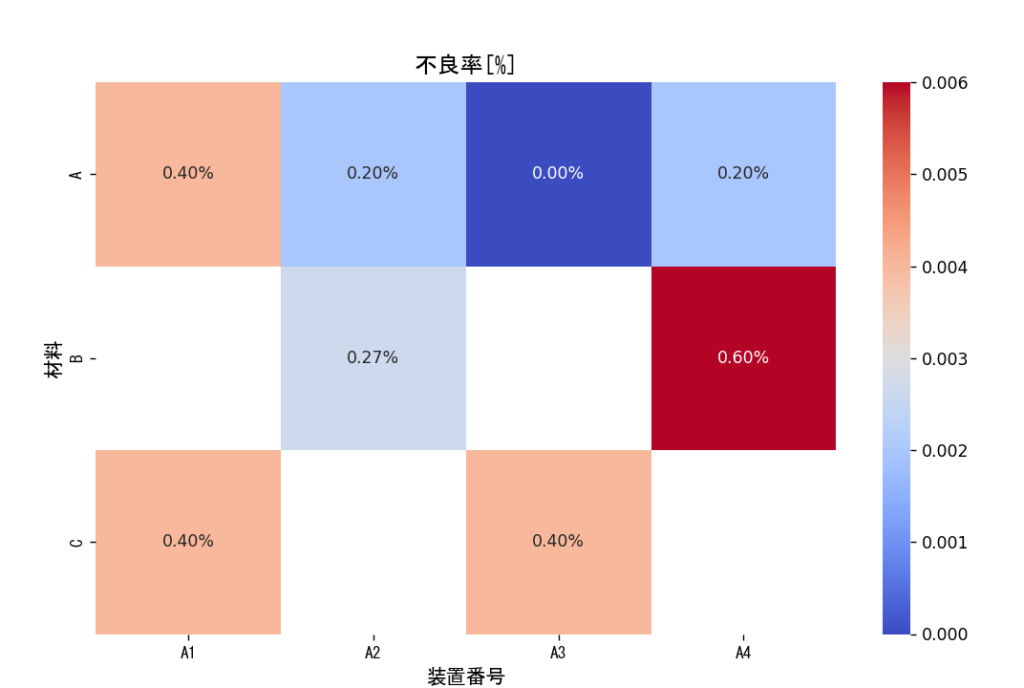
どの装置のどの材料で
上手く作れていないか
ヒートマップで
確認できるようになりました
コードを置いておきます
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
data_set_path = "sample_data.csv"
df =pd.read_csv(data_set_path,encoding ="UTF -8")
# 投入数と不良数のクロス集計
pivot_table_invested = pd.pivot_table(
df,
values='投入数',
index='材料',
columns='装置番号',
aggfunc='sum',
fill_value=0
)
pivot_table_defective = pd.pivot_table(
df,
values='不良数',
index='材料',
columns='装置番号',
aggfunc='sum',
fill_value=0
)
# 不良率の計算
pivot_table_defective_rate = pivot_table_defective / pivot_table_invested
pivot_table_defective_rate = pivot_table_defective_rate.replace(np.inf, np.nan)
print(pivot_table_defective_rate)
# 不良数が0個の場合の処理
pivot_table_defective_rate[pivot_table_defective == 0] = 0
# 投入数が0個の場合の処理
pivot_table_defective_rate[pivot_table_invested == 0] = np.nan
# ヒートマップの作成
plt.figure(figsize=(10, 6))
sns.heatmap(pivot_table_defective_rate, annot=True, fmt=".2%", cmap="coolwarm", cbar=True)
# タイトルと軸ラベルのフォントを設定
plt.title('不良率[%]', fontdict={'fontsize': 14, 'fontname': 'MS Gothic'})
plt.xlabel('装置番号', fontdict={'fontsize': 12, 'fontname': 'MS Gothic'})
plt.ylabel('材料', fontdict={'fontsize': 12, 'fontname': 'MS Gothic'})
# 軸目盛りラベルのフォントを設定
plt.xticks(fontsize=10, fontname='MS Gothic')
plt.yticks(fontsize=10, fontname='MS Gothic')
plt.show()
